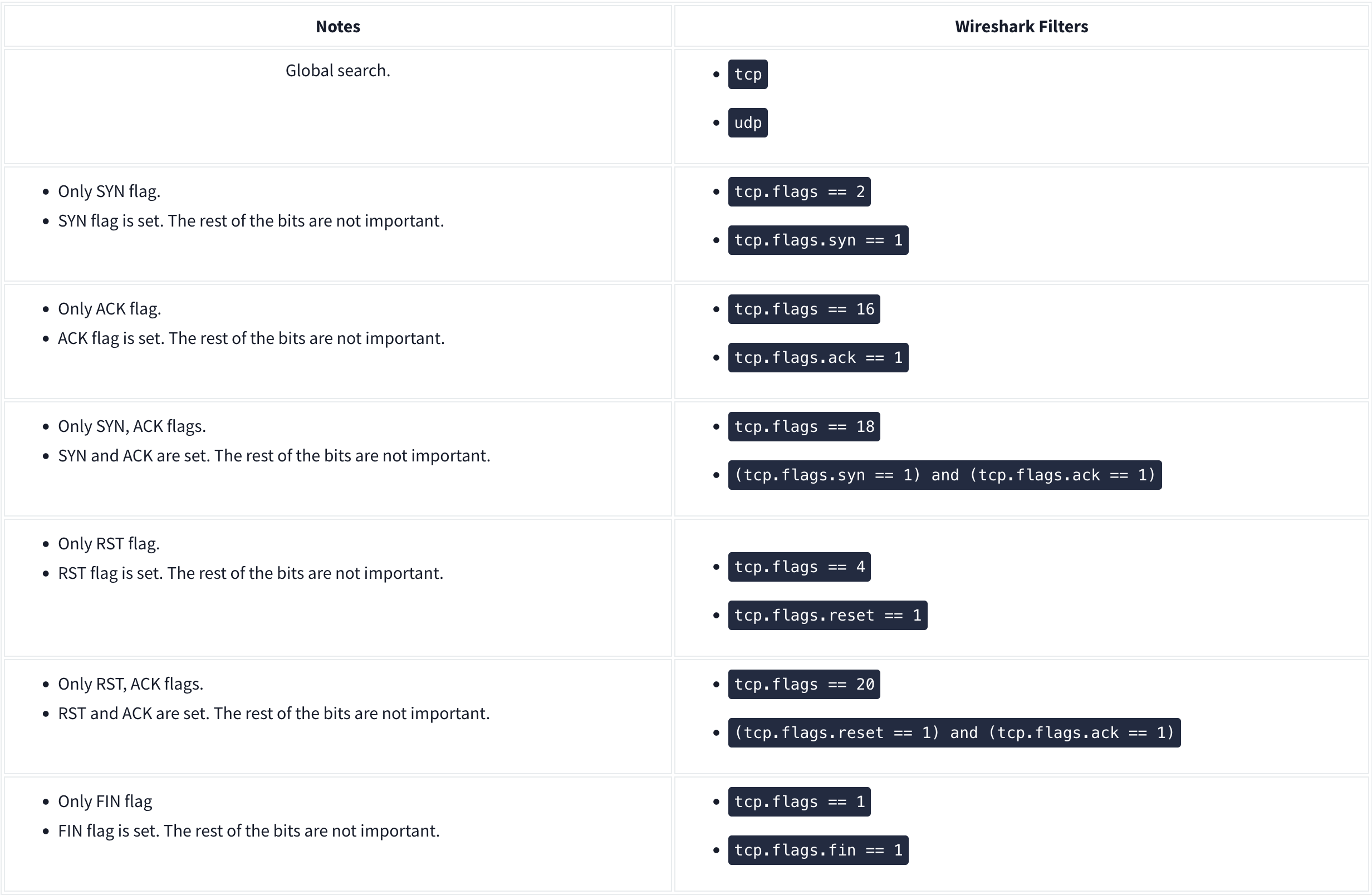
SOC Level 1
Wireshark
Nmap Scans:

Types of Scans
There are a few.
TCP Connect Scans:
- Relies on the three-way handshake (needs to finish the handshake process).
- Usually conducted with
nmap -sTcommand. - Used by non-privileged users (only option for a non-root user).
- Usually has a windows size larger than 1024 bytes as the request expects some data due to the nature of the protocol.
The given filter shows the TCP Connect scan patterns in a capture file:
tcp.flags.syn==1 and tcp.flags.ack==0 and tcp.window_size > 1024
SYN Scans:
- Doesn’t rely on the three-way handshake (no need to finish the handshake process).
- Usually conducted with
nmap -sScommand. - Used by privileged users.
- Usually have a size less than or equal to 1024 bytes as the request is not finished and it doesn’t expect to receive data.
The given filter shows the TCP SYN scan patterns in a capture file: `tcp.flags.syn==1 and tcp.flags.ack==0 and tcp.window_size <= 1024
UDP Scans
- Doesn’t require a handshake process
- No prompt for open ports
- ICMP error message for close ports
- Usually conducted with
nmap -sUcommand.
The given filter shows the UDP scan patterns in a capture file:
icmp.type==3 and icmp.code==3
ARP Poisoning and Man in the Middle
ARP analysis in a nutshell:
- Works on the local network
- Enables the communication between MAC addresses
- Not a secure protocol
- Not a routable protocol
- It doesn’t have an authentication function
- Common patterns are request & response, announcement and gratuitous packets.

Analysis
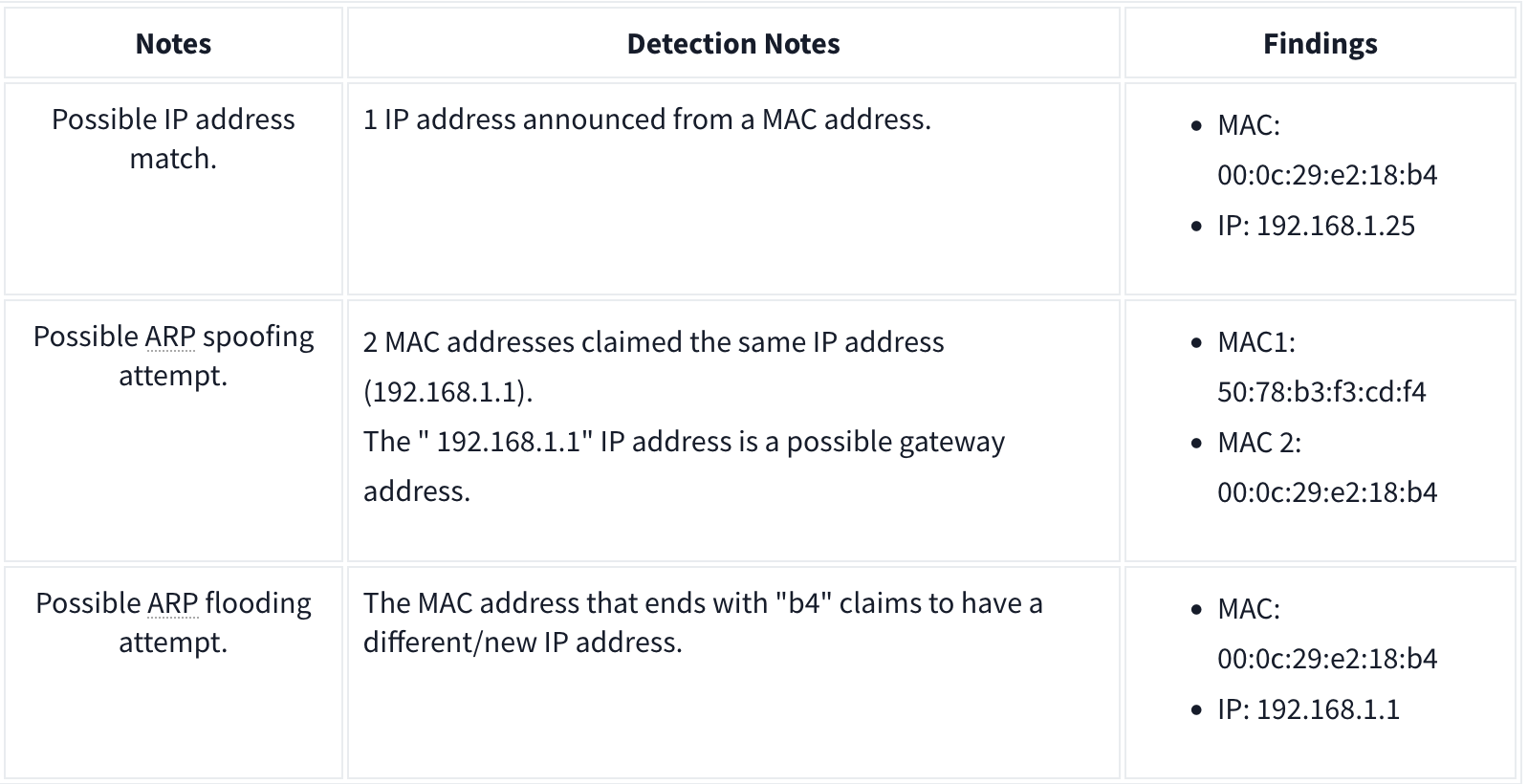
DHCP Analysis

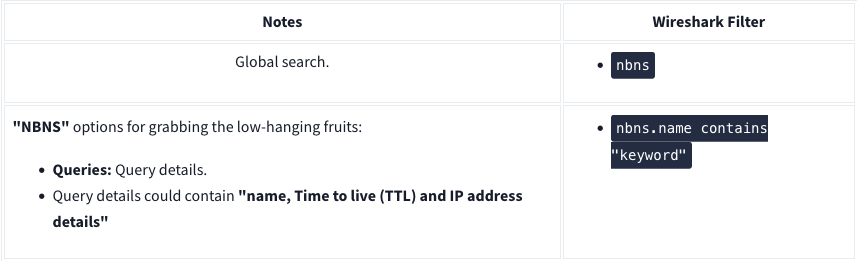
NetBIOS (NBNS) Analysis
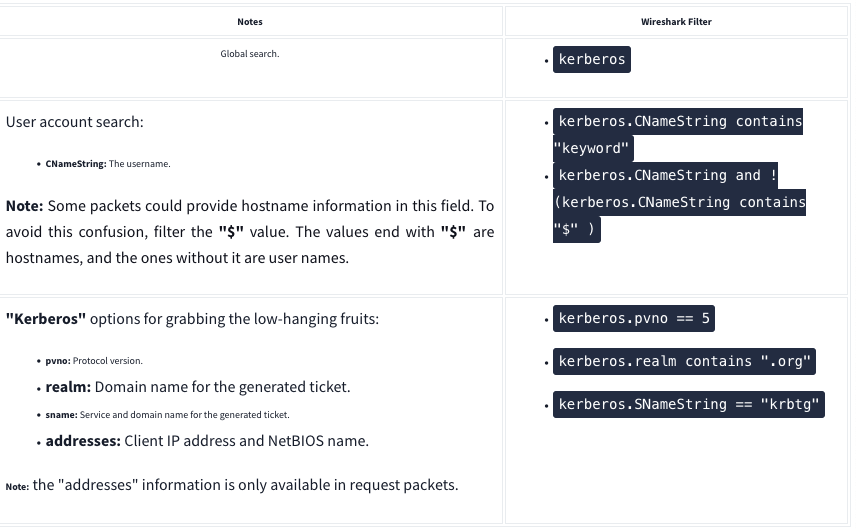
Kerberos
FTP

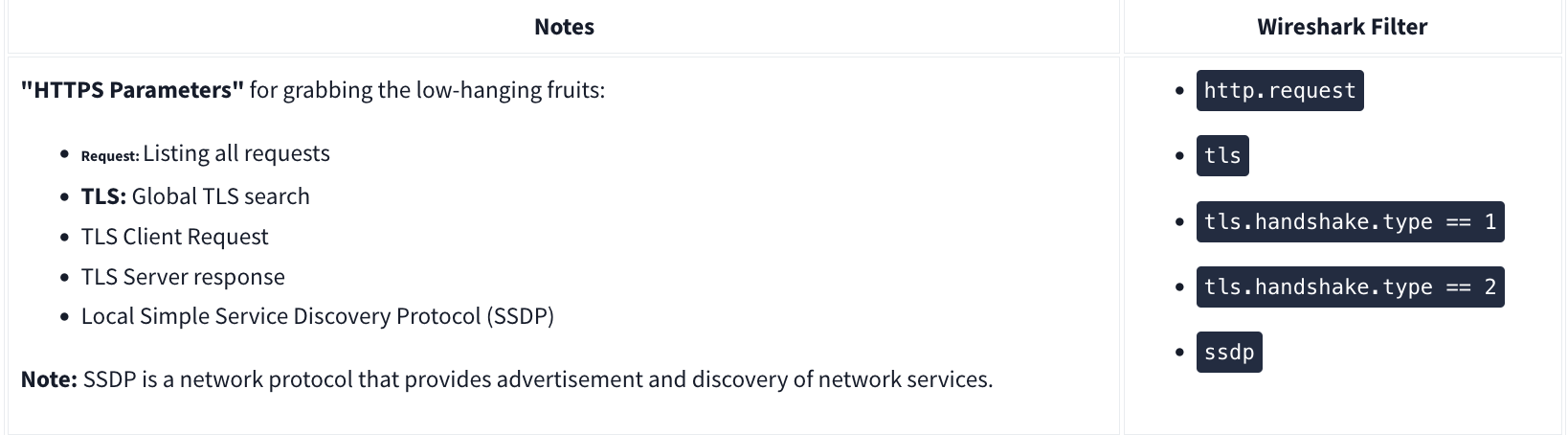
HTTP

User Agent

HTTPS
Decrypting HTTPS Traffic
Redline
Redline will essentially give an analyst a 30,000-foot view (10 kilometers high view) of a Windows, Linux, or macOS endpoint. Using Redline, you can analyze a potentially compromised endpoint through the memory dump, including various file structures.
- Collect registry data (Windows hosts only)
- Collect running processes
- Collect memory images (before Windows 10)
- Collect Browser History
- Look for suspicious strings
Data Collection
Steps:
- Pick a method (Standard, Comprehensive or IOC Search)
- Pick an OS
- Edit your script including Memory, Disk, System, Network, and Other
- Memory
- You can configure the script to collect memory data such as process listings, drivers enumeration (Windows hosts only), and hook detection (versions before Windows 10).
- Disk:
- This is where you can collect the data on Disks partitions and Volumes along with File Enumeration.
- System
- The system will provide you with machine information:
- Machine and operating system (OS) information
- Analyze system restore points (Windows versions before 10 only)
- Enumerate the registry hives (Windows only)
- Obtain user accounts (Windows and OS X only)
- Obtain groups (OS X only)
- Obtain the prefetch cache (Windows only)
- The system will provide you with machine information:
- Network:
- Network Options supports Windows, OS X, and Linux platforms. You can configure the script to collect network information and browser history, which is essential when investigating the browser activities, including malicious file downloads and inbound/outbound connections.
- Other:
- Memory
Note that for “Save Your Collector TO” the folder must be empty. Then to rn the audit (.bat file), you must run as Administrator.
Redline Interface
A handle is a connection from a process to an object or resource in a Windows operating system. Operating systems use handles for referencing internal objects like files, registry keys, resources, etc.
Some of the important sections you need to pay attention to are:
- Strings
- Ports
- File System (not included in this analysis session)
- Registry
- Windows Services
- Tasks (Threat actors like to create scheduled tasks for persistence)
- Event Logs (this another great place to look for the suspicious Windows PowerShell events as well as the Logon/Logoff, user creation events, and others)
- ARP and Route Entries (not included in this analysis session)
- Browser URL History (not included in this analysis session)
- File Download History
Phishing
There are 3 specific protocols involved to facilitate the outgoing and incoming email messages, and they are briefly listed below.
- SMTP (Simple Mail Transfer Protocol) - It is utilized to handle the sending of emails.
- Port 445
- POP3 (Post Office Protocol) - Is responsible transferring email between a client and a mail server.
- Port 995
- IMAP (Internet Message Access Protocol) - Is responsible transferring email between a client and a mail server.
- Port 993
TShark
TShark is a text-based tool, and it is suitable for data carving, in-depth packet analysis, and automation with scripts.
Basic Tools

Main Parameters
| -h | - Display the help page with the most common features. - tshark -h |
| -v | - Show version info. - tshark -v |
| -D | - List available sniffing interfaces. - tshark -D |
| -i | - Choose an interface to capture live traffic. - tshark -i 1- tshark -i ens55 |
| No Parameter | - Sniff the traffic like tcpdump. |
| -r | - Read/input function. Read a capture file. - tshark -r demo.pcapng |
| -c | - Packet count. Stop after capturing a specified number of packets. - E.g. stop after capturing/filtering/reading 10 packets. - tshark -c 10 |
| -w | - Write/output function. Write the sniffed traffic to a file. - tshark -w sample-capture.pcap |
| -V | - Verbose. - Provide detailed information for each packet. This option will provide details similar to Wireshark’s “Packet Details Pane”. - tshark -V |
| -q | - Silent mode. - Suspress the packet outputs on the terminal. - tshark -q |
| -x | - Display packet bytes. - Show packet details in hex and ASCII dump for each packet. - tshark -x |
Capture Conditions
| | |
| ————- | ——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————– |
| Parameter | Purpose |
| | Define capture conditions for a single run/loop. STOP after completing the condition. Also known as “Autostop”. |
| -a | - Duration: Sniff the traffic and stop after X seconds. Create a new file and write output to it.
- tshark -w test.pcap -a duration:1
- Filesize: Define the maximum capture file size. Stop after reaching X file size (KB).
- tshark -w test.pcap -a filesize:10
- Files: Define the maximum number of output files. Stop after X files.
- tshark -w test.pcap -a filesize:10 -a files:3 |
| | Ring buffer control options. Define capture conditions for multiple runs/loops. (INFINITE LOOP). |
| -b | - Duration: Sniff the traffic for X seconds, create a new file and write output to it.
- tshark -w test.pcap -b duration:1
- Filesize: Define the maximum capture file size. Create a new file and write output to it after reaching filesize X (KB).
- tshark -w test.pcap -b filesize:10
- Files: Define the maximum number of output files. Rewrite the first/oldest file after creating X files.
- tshark -w test.pcap -b filesize:10 -b files:3 |
Capture and Display Filters
| | | |—|—| |-f|Capture filters. Same as BPF syntax and Wireshark’s capture filters.| |-Y|Display filters. Same as Wireshark’s display filters.|
Capture
| | |
| ————————— | ————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— |
| Qualifier | Details and Available Options |
| Type | Target match type. You can filter IP addresses, hostnames, IP ranges, and port numbers. Note that if you don’t set a qualifier, the “host” qualifier will be used by default.
- host | net | port | portrange
- Filtering a host
- tshark -f "host 10.10.10.10"
- Filtering a network range
- tshark -f "net 10.10.10.0/24"
- Filtering a Port
- tshark -f "port 80"
- Filtering a port range
- tshark -f "portrange 80-100" |
| Direction | Target direction/flow. Note that if you don’t use the direction operator, it will be equal to “either” and cover both directions.
- src | dst
- Filtering source address
- tshark -f "src host 10.10.10.10"
- Filtering destination address
- tshark -f "dst host 10.10.10.10" |
| Protocol | Target protocol.
- arp | ether | icmp | ip | ip6 | tcp | udp
- Filtering TCP
- tshark -f "tcp"
- Filtering MAC address
- tshark -f "ether host F8:DB:C5:A2:5D:81"
- You can also filter protocols with IP Protocol numbers assigned by IANA.
- Filtering IP Protocols 1 (ICMP)
- tshark -f "ip proto 1"
- Assigned Internet Protocol Numbers |
| | |
| Capture Filter Category | Details |
| Host Filtering | Capturing traffic to or from a specific host.
- Traffic generation with cURL. This command sends a default HTTP query to a specified address.
- curl tryhackme.com
- TShark capture filter for a host
- tshark -f "host tryhackme.com" |
| IP Filtering | Capturing traffic to or from a specific port. We will use the Netcat tool to create noise on specific ports.
- Traffic generation with Netcat. Here Netcat is instructed to provide details (verbosity), and timeout is set to 5 seconds.
- nc 10.10.10.10 4444 -vw 5
- TShark capture filter for specific IP address
- tshark -f "host 10.10.10.10" |
| Port Filtering | Capturing traffic to or from a specific port. We will use the Netcat tool to create noise on specific ports.
- Traffic generation with Netcat. Here Netcat is instructed to provide details (verbosity), and timeout is set to 5 seconds.
- nc 10.10.10.10 4444 -vw 5
- TShark capture filter for port 4444
- tshark -f "port 4444" |
| Protocol Filtering | Capturing traffic to or from a specific protocol. We will use the Netcat tool to create noise on specific ports.
- Traffic generation with Netcat. Here Netcat is instructed to use UDP, provide details (verbosity), and timeout is set to 5 seconds.
- nc -u 10.10.10.10 4444 -vw 5
- TShark capture filter for
- tshark -f "udp" |
Display Filters
| Display Filter Category | Details and Available Options |
| Protocol: IP | - Filtering an IP without specifying a direction. - tshark -Y 'ip.addr == 10.10.10.10'- Filtering a network range - tshark -Y 'ip.addr == 10.10.10.0/24'- Filtering a source IP - tshark -Y 'ip.src == 10.10.10.10'- Filtering a destination IP - tshark -Y 'ip.dst == 10.10.10.10' |
| Protocol: TCP | - Filtering TCP port - tshark -Y 'tcp.port == 80'- Filtering source TCP port - tshark -Y 'tcp.srcport == 80' |
| Protocol: HTTP | - Filtering HTTP packets - tshark -Y 'http'- Filtering HTTP packets with response code “200” - tshark -Y "http.response.code == 200" |
| Protocol: DNS | - Filtering DNS packets - tshark -Y 'dns'- Filtering all DNS “A” packets - tshark -Y 'dns.qry.type == 1' |
CLI Wireshark Features
| Parameter | Purpose |
|---|---|
| –color | - Wireshark-like colourised output. - tshark --color |
| -z | - Statistics - There are multiple options available under this parameter. You can view the available filters under this parameter with: - tshark -z help- Sample usage. - tshark -z filter- Each time you filter the statistics, packets are shown first, then the statistics provided. You can suppress packets and focus on the statistics by using the -q parameter. |
-
Statistics Protocol Hierarchy - Protocol hierarchy helps analysts to see the protocols used, frame numbers, and size of packets in a tree view based on packet numbers. As it provides a summary of the capture, it can help analysts decide the focus point for an event of interest. Use the
-z io,phs -qparameters to view the protocol hierarchy.
- Protocol hierarchy helps analysts to see the protocols used, frame numbers, and size of packets in a tree view based on packet numbers. As it provides a summary of the capture, it can help analysts decide the focus point for an event of interest. Use the
-
Statistics Packet Lengths Tree - The packet lengths tree view helps analysts to overview the general distribution of packets by size in a tree view. It allows analysts to detect anomalously big and small packets at a glance! Use the
-z plen,tree -qparameters to view the packet lengths tree.
- The packet lengths tree view helps analysts to overview the general distribution of packets by size in a tree view. It allows analysts to detect anomalously big and small packets at a glance! Use the
-
Statistics Endpoints - The endpoint statistics view helps analysts to overview the unique endpoints. It also shows the number of packets associated with each endpoint. Use the
-z endpoints,ip -qparameters to view IP endpoints. Note that you can choose other available protocols as well.
- The endpoint statistics view helps analysts to overview the unique endpoints. It also shows the number of packets associated with each endpoint. Use the
| Filter | Purpose |
|---|---|
| eth | - Ethernet addresses |
| ip | - IPv4 addresses |
| ipv6 | - IPv6 addresses |
| tcp | - TCP addresses - Valid for both IPv4 and IPv6 |
| udp | - UDP addresses - Valid for both IPv4 and IPv6 |
| wlan | - IEEE 802.11 addresses |
Statistics
| | Parameters |
| ———————————– | ———————— |
| Conversations | -z conv,ip -q |
| Expert Info | -z expert -q |
| IPv4 | -z ip_hosts,tree -q |
| IPv6 | -z ipv6_hosts,tree -q |
| IPv4 SRC and DST | -z ip_srcdst,tree -q |
| IPv6 SRC and DST | -z ipv6_srcdst,tree -q |
| Outgoing IPv4 | -z dests,tree -q |
| Outgoing IPv6 | -z ipv6_dests,tree -q |
| DNS | -z dns,tree -q |
| Packet and status counter for HTTP | -z http,tree -q |
| Packet and status counter for HTTP2 | -z http2,tree -q |
| Load distribution | -z http_srv,tree -q |
| Requests | -z http_req,tree -q |
| Requests and responses | -z http_seq,tree -q |
Follow Stream
| Main Parameter | Protocol | View Mode | Stream Number | Additional Parameter |
| —————— | ———————————– | —————- | ——————– | ———————— |
| -z follow | - TCP
- UDP
- HTTP
- HTTP2 | - HEX
- ASCII | 0 | 1 | 2 | 3 … | -q |
- TCP Streams:
-z follow,tcp,ascii,0 -q - UDP Streams:
-z follow,udp,ascii,0 -q - HTTP Streams:
-z follow,http,ascii,0 -q
Export Objects
| Main Parameter | Protocol | Target Folder | Additional Parameter |
| —————— | ——————————————— | ——————————– | ———————— |
| –export-objects | - DICOM
- HTTP
- IMF
- SMB
- TFTP | Target folder to save the files. | -q |
Example: tshark -r demo.pcapng --export-objects http,/home/ubuntu/Desktop/extracted-by-tshark -q
Credentials
-z credentials -q
Advanced Filtering
| Filter | Details |
| ———— | ————————————————————————————————————————— |
| Contains | - Search a value inside packets.
- Case sensitive.
- Similar to Wireshark’s “find” option. |
| Matches | - Search a pattern inside packets.
- Supports regex.
- Case insensitive.
- Complex queries have a margin of error. |
Extract Fields
| Main Filter | Target Field | Show Field Name |
|---|---|---|
| -T fields | -e |
-E header=y |
Example: tshark -r demo.pcapng -T fields -e ip,src -e ip,dst -E header=y -c5
Extract hostnames: tshark -r demo.pcapng -T fields -e dhcp.option.hostname
Extract DNS queries: tshark -r dns-queries.pcap -T fields -e dns.qry.name | awk NF | sort -r | uniq -c | sort -r
awk NFto remove empty lines Extract User Agents:tshark -r demo.pcapng -T fields -e http.user_agent | awk NF | sort-r | uniq -c | sort -r
Filter: contains
| Filter | contains |
| ———– | ——————————————————————————————————————————————– |
| Type | Comparison operator |
| Description | Search a value inside packets. It is case-sensitive and provides similar functionality to the “Find” option by focusing on a specific field. |
| Example | Find all “Apache” servers. |
| Workflow | List all HTTP packets where the “server” field contains the “Apache” keyword. |
| Usage | http.server contains "Apache" |
Ex: tshark -r demo.pcang -Y 'http.server contains "Apache"'
Filter: matches
| Filter | matches |
|---|---|
| Type | Comparison operator |
| Description | Search a pattern of a regular expression. It is case-insensitive, and complex queries have a margin of error. |
| Example | Find all .php and .html pages. |
| Workflow | List all HTTP packets where the “request method” field matches the keywords “GET” or “POST”. |
| Usage | http.request.method matches "(GET\|POST)" |
Ex: tshark -r demo.pcapng -Y 'http.request.method matches "(GET|POST)"' -T fields -e ip.src -e ip.dst -e http.request.method -E header=y
Windows x64 Assembly
To distinguish between different number systems, we use prefixes or suffixes. There are many things used to distinguish between the number systems, I will only show the most common.
- Decimal is represented with the suffix “d” or with nothing. Examples: 12d or 12.
- Hexadecimal is represented with the prefix “0x” or suffix “h”. Examples: 0x12 or 12h. Another way hexadecimal is represented is with the prefix of “\x”. However, this is typically used per byte. Two hexadecimal digits make one byte. Examples: \x12 or \x12\x45\x21. If bits and bytes seem a little weird we’ll get into them soon so don’t worry.
- Binary is represented with a suffix “b” or with padding of zeros at the start. Examples: 100101b or 00100101. The padding at the start is often used because a decimal number can’t start with a zero.
What is decimal 25 in hexadecimal? Include the prefix for hexadecimal.
- 0x19
Data type sizes vary based on architecture. These are the most common sizes and are what you will come across when working with desktop Windows and Linux.
- Bit is one binary digit. Can be 0 or 1.
- Nibble is 4 bits.
- Byte is 8 bits.
- Word is 2 bytes.
- Double Word (DWORD) is 4 bytes. Twice the size of a word.
- Quad Word (QWORD) is 8 bytes. Four times the size of a word.
Data Type Sizes
- Char - 1 byte (8 bits).
- Int - There are 16-bit, 32-bit, and 64-bit integers. When talking about integers, it’s usually 32-bit. For signed integers, one bit is used to specify whether the integer is positive or negative.
- Signed Int
- 16 bit is -32,768 to 32,767.
- 32 bit is -2,147,483,648 to 2,147,483,647.
- 64-bit is -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807.
- Unsigned Int - Minimum is zero, maximum is twice that of a signed int (of the same size). For example: unsigned 32-bit int goes from 0 to 4,294,967,295. That is twice the signed int maximum of 2,147,483,647, however, its minimum value is 0. This is due to signed integers using the sign bit, making it unavailable to represent a value.
- Signed Int
- Bool - 1 byte. Interestingly, a bool only needs 1 bit because it’s either 1 or 0 but it still takes up a full byte. This is because computers don’t tend to work with individual bits due to alignment (talked about later). So instead, they work in chunks such as 1 byte, 2 bytes, 4 bytes, 8 bytes, and so on.
Data positions are referenced by how far away they are from the address of the first byte of data, known as the base address (or just the address), of the variable. The distance a piece of data is from its base address is considered the offset. For example, let’s say we have some data, 12345678. Just to push the point, let’s also say each number is 2 bytes.
- 1 is at offset 0x0
- 2 is at offset 0x2
- 3 is at offset 0x4
- 4 is at offset 0x6, and so on. You could reference these values with the format BaseAddress+0x##. BaseAddress+0x0 or just BaseAddress would contain the 1, BaseAddress+0x2 would be the 2, and so on.
C vs. Assembly
Small example:
if(x == 4){
func1();
}else{
return;
}
is functionally the same as the following pseudo-assembly:
mov RAX, x
cmp RAX, 4
jne 5 ; Line 5 (ret)
call func1
ret
This should be fairly self-explanatory, but I’ll go over it briefly. First, the variable x is moved into RAX. RAX is a register, think of it as a variable in assembly. Then, we compare that with 4. If the comparison between RAX (4) and 5 results in them not being equal then jump (jne) to line 5 which returns. Otherwise, they are equal, so call func1().
The Registers
Let’s talk about General Purpose Registers (GPR). You can think of these as variables because that’s essentially what they are. The CPU has its own storage that is extremely fast. This is great, however, space in the CPU is extremely limited. Any data that’s too big to fit in a register is stored in memory (RAM). Accessing memory is much slower for the CPU compared to accessing a register. Because of the slow speed, the CPU tries to put data in registers instead of memory if it can. If the data is too large to fit in a register, a register will hold a pointer to the data so it can be accessed.
8 Main General-Purpose Registers
- RAX - Known as the accumulator register. Often used to store the return value of a function.
- RBX - Sometimes known as the base register, not to be confused with the base pointer. Sometimes used as a base pointer for memory access.
- RDX - Sometimes known as the data register.
- RCX - Sometimes known as the counter register. Used as a loop counter.
- RSI - Known as the source index. Used as the source pointer in string operations.
- RDI - Known as the destination index. Used as the destination pointer in string operations.
- RSP - The stack pointer. Holds the address of the top of the stack.
- RBP - The base pointer. Holds the address of the base (bottom) of the stack.
Each register can be broken down into smaller segments which can be referenced with other register names. RAX is 64 bits, the lower 32 bits can be referenced with EAX, and the lower 16 bits can be referenced with AX. AX is broken down into two 8 bit portions. The high/upper 8 bits of AX can be referenced with AH. The lower 8 bits can be referenced with AL.
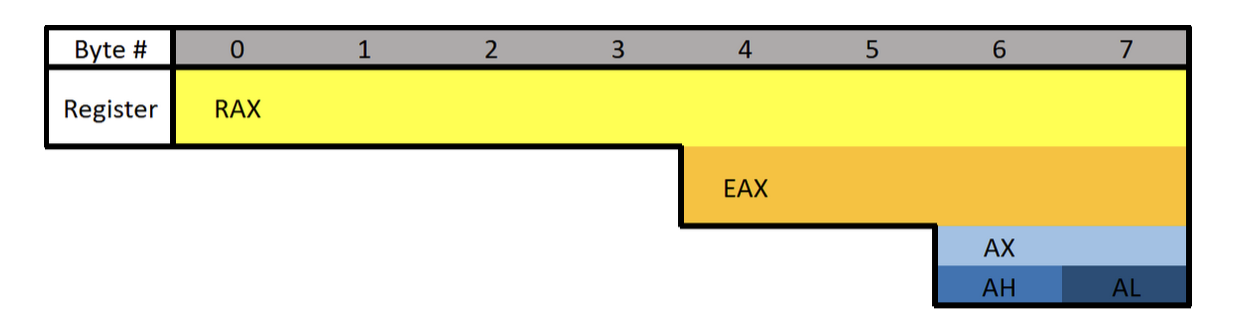
What is the difference between the “E” and “R” prefixes? Besides one being a 64-bit register and the other 32 bits, the “E” stands for extended. The “R” stands for register. The “R” registers were newly introduced in x64, and no, you won’t see them on 32-bit systems.
Floating-point values are represented differently than integers. Because of this, floating-point values have special registers. These registers include YMM0 to YMM15 (64-bit) and XMM0 to XMM15 (32-bit). The XMM registers are the lower half of the YMM registers, similar to how EAX is the lower 32 bits of RAX. Something unique about these registers is that they can be treated as arrays.
Extra Registers
There are additional registers that should be mentioned. These registers don’t have any special uses. There are registers r8 to r15 which are designed to be used by integer type values (not floats or doubles). The lower 4 bytes (32 bits), 2 bytes (16 bits), and 8 bits (1 byte) can all be accessed. These can be accessed by appending the letter “d”, “w”, or “b”.
Examples:
- R8 - Full 64-bit (8 bytes) register.
- R8D - Lower double word (4 bytes).
- R8W - Lower word (2 bytes)
- R8B - Lower byte.
Instructions
Before we get started there are three different terms you should know: immediate, register, and memory.
- An immediate value (or just immediate, sometimes IM) is something like the number 12. An immediate value is not a memory address or register, instead, it’s some sort of constant data.
- A register is referring to something like RAX, RBX, R12, AL, etc.
- Memory or a memory address refers to a location in memory (a memory address) such as 0x7FFF842B.
;is used to write a comment in Assembly- Syntax is:
(Instruction/Opcode/Mnemonic) <Destination Operand>, <Source Operand>
Data Movement
MOV is used to move/store the source operand into the destination. The source doesn’t have to be an immediate value like it is in the following example. In the following example, the immediate value of 5 is being moved into RAX.
This is equivalent to RAX = 5.
mov RAX, 5
LEA is short for Load Effective Address. This is essentially the same as MOV except for addresses. They key difference between MOV and LEA is that LEA doesn’t dereference. It’s also commonly used to compute addresses. In the following example, RAX will contain the memory address/location of num1.
lea RAX, num1
lea RAX, [struct+8]
mov RBX, 5
lea RAX, [RBX+1]
In the first example, RAX is set to the address of num1. In the second, RAX is set to the address of the member in a structure which is 8 bytes from the start of the structure. This would usually be the second member. The third example RBX is set to 5, then LEA is used to set RAX to RBX + 1. RAX will be 6.
PUSH is used to push data onto the stack. Pushing refers to putting something on the top of the stack. In the following example, RAX is pushed onto the stack. Pushing will act as a copy so RAX will still contain the value it had before it was pushed. Pushing is often used to save the data inside a register by pushing it onto the stack, then later restoring it with pop.
push RAX
POP is used to take whatever is on the top of the stack and store it in the destination. In the following example whatever is on the top of the stack will be put into RAX.
pop RAX
Arithmetic:
INC will increment data by one. In the following example RAX is set to 8, then incremented. RAX will be 9 by the end.
mov RAX, 8
inc RAX
DEC decrements a value. In the following example, RAX ends with a value of 7.
mov RAX, 8
dec RAX
ADD adds a source to a destination and stores the result in the destination. In the following example, 2 is moved into RAX, 3 into RBX, then they are added together. The result (5) is then stored in RAX.
Same as RAX = RAX + RBX or RAX += RBX.
mov RAX, 2
mov RBX, 3
add RAX, RBX
SUB subtracts a source from a destination and stores the result in the destination. In the following example, RAX will end with a value of 2.
Same as RAX = RAX - RBX or RAX -= RBX.
mov RAX, 5
mov RBX, 3
sub RAX, RBX
Multiplication and division are a bit different.
Because the sizes of data can vary and change greatly when multiplying and dividing, they use a concatenation of two registers to store the result. The upper half of the result is stored in RDX, and the lower half is in RAX. The total result of the operation is RDX:RAX, however, referencing just RAX is usually good enough. Furthermore, only one operand is given to the instruction. Whatever you want to multiply or divide is stored in RAX, and what you want to multiply or divide by is passed as the operand. Examples are provided in the following descriptions.
MUL (unsigned) or IMUL (signed) multiplies RAX by the operand. The result is stored in RDX:RAX. In the following example, RDX:RAX will end with a value of 125.
The following is the same as 25*5
mov RAX, 25
mov RBX, 5
mul RBX ; Multiplies RAX (25) with RBX (5)
After that code runs, the result is stored in RDX:RAX but in this case, and in most cases, RAX is enough.
DIV (unsigned) and IDIV (unsigned) work the same as MUL. What you want to divide (dividend) is stored in RAX, and what you want to divide it by (divisor) is passed as the operand. The result is stored in RDX:RAX, but once again RAX alone is usually enough.
mov RAX, 18
mov RBX, 3
div RBX ; Divides RAX (18) by RBX (3)
After that code executes, RAX would be 6.
#####
Flow Control:
RET is short for return. This will return execution to the function that called the currently executing function, aka the caller. As you will soon learn, one of the purposes of RAX is to hold return values. The following example sets RAX to 10 then returns. This is equivalent to return 10; in higher-level programming languages.
mov RAX, 10 ret
CMP compares two operands and sets the appropriate flags depending on the result. The following would set the Zero Flag (ZF) to 1 which means the comparison determined that RAX was equal to five. Flags are talked about in the next section. In short, flags are used to represent the result of a comparison, such as if the two numbers were equal or not.
mov RAX, 5
cmp RAX, 5
JCC instructions are conditional jumps that jump based on the flags that are currently set. JCC is not an instruction, rather a term used to mean the set of instructions that includes JNE, JLE, JNZ, and many more. JCC instructions are usually self-explanatory to read. JNE will jump if the comparison is not equal, and JLE jumps if less than or equal, JG jumps if greater, etc. This is the assembly version of if statements.
The following example will return if RAX isn’t equal to 5. If it is equal to 5 then it will set RBX to 10, then return.
mov RAX, 5
cmp RAX, 5
jne 5 ; Jump to line 5 (ret) if not equal.
mov RBX, 10
ret
NOP is short for No Operation. This instruction effectively does nothing. It’s typically used for padding because some parts of code like to be on specific boundaries such as 16-bit or 32-bit boundaries.
Efficiency
Instead of what a programmer would typically write:
if(x == 4){
func1();
}
else{
return;
}
The compiler will generate something closer to:
if(x != 4){
goto __exit;
}
func1();
__exit:
return;
The compiler generates code this way because it’s almost always more efficient and skips more code. The above examples may not see much of a performance improvement over one another, however, in larger programs the improvement can be quite significant.
Pointers
Assembly has its ways of working with pointers and memory addresses as C/C++ does. In C/C++ you can use dereferencing to get the value inside of a memory address. For example:
int main(){
int num = 10;
int* ptr = &num
return (*ptr + 5);
}
-
ptris a pointer tonum, which meansptris holding the memory address ofnum. -
Then return the sum of what’s at the address inside
ptr(numwhich is 10) and 5.
Two of the most important things to know when working with pointers and addresses in Assembly are LEA and square brackets.
-
Square Brackets - Square brackets dereference in assembly. For example,
[var]is the address pointed to by var. In other words, when using[var]we want to access the memory address thatvaris holding. -
LEA - Ignore everything about square brackets when working with LEA. LEA is short for Load Effective Address and it’s used for calculating and loading addresses.
It’s important to note that when working with the LEA instruction, square brackets do not dereference.
The JMP’s Mason, what do they mean?!
Let’s talk about the difference between instructions such as jg (jump if greater) and ja (jump if above). Knowing the difference can help you snipe those hard-to-understand data types. There are other instructions like this so be sure to look up what they do when you come across them. For example, there are several variants of mov.
Here’s the rundown for the jump instructions when it comes to signed or unsigned. Ignore the “CF” and “ZF” if you don’t know what they mean, I’ve included them for reference after you understand flags (covered next).
For unsigned comparisons:
-
JB/JNAE (CF = 1) ; Jump if below/not above or equal
-
JAE/JNB (CF = 0) ; Jump if above or equal/not below
-
JBE/JNA (CF = 1 or ZF = 1) ; Jump if below or equal/not above
-
JA/JNBE (CF = 0 and ZF = 0); Jump if above/not below or equal
For signed comparisons:
JL/JNGE (SF <> OF) ; Jump if less/not greater or equal
JGE/JNL (SF = OF) ; Jump if greater or equal/not less
JLE/JNG (ZF = 1 or SF <> OF); Jump if less or equal/not greater
JG/JNLE (ZF = 0 and SF = OF); Jump if greater/not less or equal
Easy way to remember this, and how I remember it:
Humans normally work with signed numbers, and we usually say greater than or less than. That’s how I remember signed goes with the greater than and less than jumps.
Flags
Flags are used to signify the result of the previously executed operation or comparison. For example, if two numbers are compared to each other the flags will reflect the results such as them being even. Flags are contained in a register called EFLAGS (x86) or RFLAGS (x64). I usually just refer to it as the flags register. There is an actual FLAGS register that is 16 bit, but the semantics are just a waste of time. If you want to get into that stuff, look it up, Wikipedia has a good article on it. I’ll tell you what you need to know.
Status Flags
Here are the flags you should know. Note that when I say a “flag is set” I mean the flag is set to 1 which is true/on. 0 is false/off.
- Zero Flag (ZF) - Set if the result of an operation is zero. Not set if the result of an operation is not zero.
- Carry Flag (CF) - Set if the last unsigned arithmetic operation carried (addition) or borrowed (subtraction) a bit beyond the register. It’s also set when an operation would be negative if it wasn’t for the operation being unsigned.
- Overflow Flag (OF) - Set if a signed arithmetic operation is too big for the register to contain.
- Sign Flag (SF) - Set if the result of an operation is negative.
- Adjust/Auxiliary Flag (AF) - Same as the carry flag but for Binary Coded Decimal (BCD) operations.
- Parity Flag (PF) - Set to 1 if the number of bits set in the last 8 bits is even. (10110100, PF=1; 10110101, PF=0)
- Trap Flag (TF) - Allows for single-stepping of programs.
For a full list of flags see: https://www.tech-recipes.com/rx/1239/assembly-flags/
Examples
Basic Comparison
Here are some examples to demonstrate flags being set.
Here’s the first example. The following code is trying to determine if RAX is equal to 4. Since we’re testing for equality, the ZF is going to be the most important flag.
On line 2 there is a CMP instruction that is going to be testing for equality between RAX and the number 4. The way in which CMP works is by subtracting the two values. So when cmp RAX, 4 runs, 4 is subtracted from RAX (also 4). This is why the comparison results in zero because the subtraction process literally results in zero. Since the result is zero, the ZF flag is set to 1 (on/true) to denote that the operation resulted in the value of 0, also meaning the values were equal! That brings us to the JNE, which jumps if not equal/zero. Since the ZF is set it will not jump, since they are equal, and therefore the call to func1() is made. If they were not equal, the jump would be taken which would jump over the function call straight to the return.
mov RAX, 4
cmp RAX, 4
jne 5 ; Line 5 (ret)
call func1
ret
; ZF = 1, OF = 0, SF = 0
Subtraction
The following example will be demonstrating a signed operation. SF will be set to 1 because the subtraction operation results in a negative number. Using the cmp instruction instead of sub would have the same results, except the value of the operation (-6) wouldn’t be saved in any register.
mov RAX, 2
sub RAX, 8 ; 2 - 8 = -6.
; ZF = 0, OF = 0, SF = 1
Addition
The following is an example where the result is too big to fit into a register. Here I’m using 8-bit registers so we can work with small numbers. The biggest number that can fit in a signed 8-bit register is 128. AL is loaded with 75 then 60 is added to it. The result of adding the two together should result in 135, which exceeds the maximum. Because of this, the number wraps around and AL is going to be -121. This sets the OF because the result was too big for the register, and the SF flag is set because the result is negative. If this was an unsigned operation CF would be set.
mov AL, 75
add AL, 60
; ZF = 0, OF = 1, SF = 1
Windows x64 Calling Convention
There are many calling conventions, I will cover the one used on x64 Windows in detail. Once you understand one you can understand the others very easily, it’s just a matter of remembering which is which (if you choose to).
Before we start, be aware that attention to detail is very important here.
When a function is called you could, theoretically, pass parameters via registers, the stack, or even on disk. You just need to be sure that the function you are calling knows where you’re putting the parameters. This isn’t too big of a problem if you are using your own functions, but things would get messy when you start using libraries. To solve this problem we have calling conventions that define how parameters are passed to a function, who allocates space for variables, and who cleans up the stack.
Callee refers to the function being called, and the caller is the function making the call.
There are several different calling conventions including cdecl, syscall, stdcall, fastcall, and more. Because I’ve chosen to focus on x64 Windows for simplicity, we will be working with x64 fastcall. If you plan to reverse engineer on other platforms, be sure to learn their respective calling convention(s).
You will sometimes see a double underscore prefix before a calling convention’s name. For example:
__fastcall. I won’t be doing this because it’s annoying to type.
Fastcall
Fastcall is the calling convention for x64 Windows. Windows uses a four-register fastcall calling convention by default. Quick FYI, when talking about calling conventions you will hear about something called the “Application Binary Interface” (ABI). The ABI defines various rules for programs such as calling conventions, parameter handling, and more.
How does the x64 Windows calling convention work?
- The first four parameters are passed in registers, LEFT to RIGHT. Parameters that are not floating-point values, such as integers, pointers, and chars, will be passed via RCX, RDX, R8, and R9 (in that order). Floating-point parameters will be passed via XMM0, XMM1, XMM2, and XMM3 (in that order).
- If there is a mix of floating-point and integer values, they will still be passed via the register that corresponds to their position. For example,
func(1, 3.14, 6, 6.28)will pass the first parameter through RCX, the second through XMM1, the third through R8, and the last through XMM3. - If the parameter being passed is too big to fit in a register then it is passed by reference (a pointer to the data in memory). Parameters can be passed via any sized corresponding register. For example, RCX, ECX, CX, CH, and CL can all be used for the first parameter. Any other parameters are pushed onto the stack, RIGHT to LEFT.
There is always going to be space allocated on the stack for 4 parameters, even if there aren’t any parameters. This space isn’t completely wasted because the compiler can, and often will, use it. Usually, if it’s a debug build, the compiler will put a copy of the parameters in the space. On release builds, the compiler will use it for temporary or local variable storage.
Here are some more rules of the calling convention:
- The base pointer (RBP) is saved when a function is called so it can be restored.
- A function’s return value is passed via RAX if it’s an integer, bool, char, etc., or XMM0 if it’s a float or double.
- Member functions have an implicit first parameter for the “this” pointer. Because it’s a pointer and it’s the first parameter, it will be passed via RCX. This can be very useful to know.
- The caller is responsible for allocating space for parameters for the callee. The caller must always allocate space for 4 parameters even if no parameters are passed.
- The registers RAX, RCX, RDX, R8, R9, R10, R11, and XMM0-XMM5 are considered volatile and must be considered destroyed on function calls.
- The registers RBX, RBP, RDI, RSI, RSP, R12, R13, R14, R15, and XMM6-XMM15 are considered nonvolatile and should be saved and restored by a function that uses them.
Stack Access
Data on the stack such as local variables and function parameters are often accessed with RBP or RSP. On x64 it’s extremely common to see RSP used instead of RBP to access parameters. Remember that the first four parameters, even though they are passed via registers, still have space reserved for them on the stack. This space is going to be 32 bytes (0x20), 8 bytes for each of the 4 registers. Remember this because at some point you will see this offset when accessing parameters passed on the stack.
- 1-4 Parameters:
- Arguments will be pushed via their respective registers, left to right. The compiler will likely use RSP+0x0 to RSP+0x18 for other purposes.
- More Than 4 Parameters:
- The first four arguments are passed via registers, left to right, and the rest are pushed onto the stack starting at offset RSP+0x20, right to left. This makes RSP+0x20 the fifth argument and RSP+0x28.
Here is a very simple example where the numbers 1 to 8 are passed from one function to another function. Notice the order they are put in.
function(1,2,3,4,5,6,7,8)
MOV RCX 0x1 ; Going left to right.
MOV RDX 0x2
MOV R8 0x3
MOV R9 0x4
PUSH 0x8 ; Now going right to left.
PUSH 0x7
PUSH 0x6
PUSH 0x5
CALL function
In this case, the stack parameters should be accessed via RSP+0x20 to RSP+0x28.
Putting them in registers left to right and then pushing them on the stack right to left may not make sense, but it does once you think about it. By doing this, if you were to pop the parameters off the stack they would be in order.
POP R10 ; = 5
POP R11 ; = 6
POP R12 ; = 6
POP R13 ; = 7
Now you can access them, left to right in order: RCX, RDX, R8, R9, R10, R11, R12, R13.
Beautiful :D
Further Exploration
That’s the x64 Windows fastcall calling convention in a nutshell. Learning your first calling convention is like learning your first programming language. It seems complex and daunting at first, but that’s probably because you’re overthinking it. Furthermore, it’s typically harder to learn your first calling convention than it is your second or third.
If you want to learn more about this calling convention you can here:
https://docs.microsoft.com/en-us/cpp/build/x64-calling-convention?view=vs-2019
https://docs.microsoft.com/en-us/cpp/build/x64-software-conventions?view=vs-2019
Quick reminder, it may not hurt to go back and read the registers, memory layout, and instructions sections again. Maybe even come back and read this section after those. All of these concepts are intertwined, so it can help. I know it’s annoying and sometimes frustrating to re-read, but trust me when I say it’s worth it.
cdecl (C Declaration)
After going in-depth on fastcall, here’s a quick look at cdecl.
- The parameters are passed on the stack backward (right to left).
- The base pointer (RBP) is saved so it can be restored.
- The return value is passed via EAX.
- The caller cleans the stack. This is what makes cdecl cool. Because the caller cleans the stack, cdecl allows for a variable number of parameters.
Like I said after you understand your first calling convention learning others is pretty easy. Quick reminder, this was only a brief overview of cdecl.
See here for more info:
- https://docs.microsoft.com/en-us/cpp/build/x64-software-conventions?view=vs-2019
- https://docs.microsoft.com/en-us/cpp/build/x64-calling-convention?view=vs-2019
- https://docs.microsoft.com/en-us/cpp/build/prolog-and-epilog?view=vs-2019
- https://www.gamasutra.com/view/news/171088/x64_ABI_Intro_to_the_Windows_x64_calling_convention.php
Memory Layout
The system’s memory is organized in a specific way. This is done to make sure everything has a place to reside in.
Memory Segments
There are different segments/sections in which data or code is stored in memory. They are the following:
- Stack - Holds non-static local variables. Discussed more in-depth soon.
- Heap - Contains dynamically allocated data that can be uninitialized at first.
- .data - Contains global and static data initialized to a non-zero value.
- .bss - Contains global and static data that is uninitialized or initialized to zero.
- .text - Contains the code of the program (don’t blame me for the name, I didn’t make it).
Overview of Memory Sections
Here is a general overview of how memory is laid out in Windows. This is extremely simplified.

Important:
The diagram above shows the direction variables (and any named data, even structures) are put into or taken out of memory. The actual data is put into memory differently. This is why stack diagrams vary so much. You’ll often see stack diagrams with the stack and heap growing towards each other or high memory addresses at the top. I will explain more later. The diagram I’m showing is the most relevant for reverse engineering. Low addresses being at the top is also the most realistic depiction.
Each Section Explained:
- Stack - Area in memory that can be used quickly for static data allocation. Imagine the stack with low addresses at the top and high addresses at the bottom. This is identical to a normal numerical list. Data is read and written as “last-in-first-out” (LIFO). The LIFO structure of the stack is often represented with a stack of plates. You can’t simply take out the third plate from the top, you have to take off one plate at a time to get to it. You can only access the piece of data that’s on the top of the stack, so to access other data you need to move what’s on top out of the way. When I said that the stack holds static data I’m referring to data that has a known length such as an integer. The size of an integer is defined at compile-time, the size is typically 4 bytes, so we can throw that on the stack. Unless a maximum length is specified, user input should be stored on the heap because the data has a variable size. However, the address/location of the input will probably be stored on the stack for future reference. When you put data on top of the stack you push it onto the stack. When data is pushed onto the stack, the stack grows up, towards lower memory addresses. When you remove a piece of data off the top of the stack you pop it off the stack. When data is popped off the stack, the stack shrinks down, towards higher addresses. That all may seem odd but remember, it’s like a normal numerical list where 1, the lower number, is at the top. 10, the higher number, is at the bottom. Two registers are used to keep track of the stack. The stack pointer (RSP/ESP/SP) is used to keep track of the top of the stack and the base pointer (RBP/EBP/BP) is used to keep track of the base/bottom of the stack. This means that when data is pushed onto the stack, the stack pointer is decreased since the stack grew up towards lower addresses. Likewise, the stack pointer increases when data is popped off the stack. The base pointer has no reason to change when we push or pop something to/from the stack. We’ll talk about both the stack pointer and base pointer more as time goes on.
Be warned, you will sometimes see the stack represented the other way around, but the way I’m teaching it is how you’ll see it in the real world.
- Heap - Similar to the stack but used for dynamic allocation and it’s a little slower to access. The heap is typically used for data that is dynamic (changing or unpredictable). Things such as structures and user input might be stored on the heap. If the size of the data isn’t known at compile-time, it’s usually stored on the heap. When you add data to the heap it grows towards higher addresses.
- Program Image - This is the program/executable loaded into memory. On Windows, this is typically a Portable Executable (PE).
Don’t worry too much about the TEB and PEB for now. This is just a brief introduction to them.
- TEB - The Thread Environment Block (TEB) stores information about the currently running thread(s).
- PEB - The Process Environment Block (PEB) stores information about the process and the loaded modules. One piece of information the PEB contains is “BeingDebugged” which can be used to determine if the current process is being debugged.
PEB Structure Layout: https://docs.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-peb
Here’s a quick example diagram of the stack and heap with some data on them.

In the diagram above, stackVar1 was created before stackVar2, likewise for the heap variables.
Stack Frames
Stack frames are chunks of data for functions. This data includes local variables, the saved base pointer, the return address of the caller, and function parameters. Consider the following example:
int Square(int x){
return x*x;
}
int main(){
int num = 5;
Square(5);
}
In this example, the main() function is called first. When main() is called, a stack frame is created for it. The stack frame for main(), before the function call to Square(), includes the local variable num and the parameters passed to it (in this case there are no parameters passed to main). When main() calls Square() the base pointer (RBP) and the return address are both saved. Remember, the base pointer points to the base/bottom of the stack. The base pointer is saved because when a function is called, the base pointer is updated to point to the base of that function’s stack. Once the function returns, the base pointer is restored so it points to the base of the caller’s stack frame. The return address is saved so once the function returns, the program knows where to resume execution. The return address is the next instruction after the function call. So in this case the return address is the end of the main() function. That may sound confusing, hopefully, this can clear it up:
mov RAX, 15 ;RAX = 15
call func ;Call func. Same as func();
mov RBX, 23 ;RBX = 23. This line is saved as the return address for the function call.
I know that this can be a bit confusing but it is quite simple in how it works. It just may not be intuitive at first. It’s simply telling the computer where to go (what instruction to execute) when the function returns. You don’t want it to execute the instruction that called the function because that will cause an infinite loop. This is why the next instruction is used as the return address instead. So in the above example, RAX is set to 15, then the function called func is called. Once it returns it’s going to start executing at the return address which is the line that contains mov RBX, 23.
Here is the layout of a stack frame:

Note the location of everything. This will be helpful in the future.
Endianness
Given the value of 0xDEADBEEF, how should it be stored in memory? This has been debated for a while and still strikes arguments today. At first, it may seem intuitive to store it as it is, but when you think of it from a computer’s perspective it’s not so straightforward. Because of this, there are two ways computers can store data in memory - big-endian and little-endian.
- Big Endian - The most significant byte (far left) is stored first. This would be 0xDEADBEEF from the example.
- Little Endian - The least significant byte (far right) is stored first. This would be 0xEFBEADDE from the example.
You can learn more about endianness here: https://www.youtube.com/watch?v=NcaiHcBvDR4
Data Storage
As promised, I’ll explain how data is written into memory. It’s slightly different than how space is allocated for data. As a quick recap, space is allocated on the stack for variables from bottom to top, or higher addresses to lower addresses.
Data is put into this allocated space very simply. It’s just like writing English: left to right, top to bottom. The first piece of data in a variable or structure is at the lowest address in memory compared to the rest of the data. As data gets added, it’s put at a higher address further down the stack.

This diagram illustrates two things. First, how data is put into its allocated space. Second, a side effect of how data is put into its allocated memory. I’ll break down the diagram. On the left are the variables being created. On the right are the results of those variable creations. I’ll just focus on the stack for this explanation.
- On the left three variables are given values. The first variable, as previously explained, is put on the bottom. The next variable is put on top of that, and the next on top of that.
- After allocating the space for the variables, data is put into those variables. It’s all pretty simple but something interesting is going on with the array. Notice how it only allocated an array of 2 elements
stackArr[2], but it was given 3= {3,4,5}. Because data is written from lower addresses to higher or left to right and top to bottom, it overwrites the data of the variable below it. So instead ofstackVar2being 2, it’s overwritten by the 5 that was intended to be instackArr[2].
Hopefully that all makes sense. Here’s a quick recap:
Variables are allocated on the stack one on top of the other like a stack of trays. This means they’re put on the stack starting from higher addresses and going to lower addresses.
Data is put into the variables from left to right, top to bottom. That is, from lower to higher addresses.
It’s a simple concept, try not to over-complicate it just because I’ve given a long explanation. It’s vital you understand it, which is why I’ve taken so much time to explain this concept. It’s because of these concepts that there are so many depictions of memory out there that go in different directions.
RBP & RSP on x64
On x64, it’s common to see RBP used in a non-traditional way (compared to x86). Sometimes only RSP is used to point to data on the stack such as local variables and function parameters, and RBP is used for general data (similar to RAX). This will be discussed in further detail later.
Other Terms
Endianness - how does your computer store values that are larger than one byte. Note that the e is the least signifcant byte, like least significant digit.
0x00c0ffee
Big Endian: 0x 00 c0 ff ee
Little Endian: 0x ee ff c0 00
Snort Cheat Sheet
- Write a single rule to detect “all TCP port 80 traffic” packets in the given pcap file.
alert tcp any any <> any 80 (msg: "TCP Port 80 Activity Detected"; sid: 100001; rev:1;)
- Write a single rule to detect “all TCP port 21“ traffic in the given pcap.
alert tcp any any <> any 21 (msg: "FTP Port 21 Activity Detected"; sid: 1000001;)
- Write a rule to detect failed FTP login attempts in the given pcap.
alert tcp any any <> any 21 (msg: "Failed FTP login attempt";content:"530";sid:1000001;)
- Write a rule to detect FTP login attempts with the “Administrator” username but no password entered yet.
alert tcp any any <> 21 (msg: "Failed FTP Administrator login";content:"Administrator";content:"331";sid:1000001;)
- Write a rule to detect the PNG file in the given pcap.
alert tcp any any <> any any (msg:"PNG File Detected"; content:"|89 50 4E 47 0D 0A 1A 0A|"; depth:8;sid:1000001;)
- Write a rule to detect the GIF file in the given pcap.
alert tcp any any -> any any (msg:"GIF File Detected"; content:"GIF";sid:1000001;)
Velociraptor
Velociraptor is a unique, advanced open-source endpoint monitoring, digital forensic and cyber response platform. It was developed by Digital Forensic and Incident Response (DFIR) professionals who needed a powerful and efficient way to hunt for specific artifacts and monitor activities across fleets of endpoints. Velociraptor provides you with the ability to more effectively respond to a wide range of digital forensic and cyber incident response investigations and data breaches.
Velociraptor is unique because the Velociraptor executable can act as a server or a client and it can run on Windows, Linux, and MacOS.
Instant Velociraptor (only on host) - velociraptor.exe gui
Brim
Brim is an open-source desktop application that processes pcap files and logs files, with a primary focus on providing search and analytics. It uses the Zeek log processing format. It also supports Zeek signatures and Suricata Rules for detection.
It can handle two types of data as an input;
- Packet Capture Files: Pcap files created with tcpdump, tshark and Wireshark like applications.
- Log Files: Structured log files like Zeek logs.
Brim is built on open-source platforms:
- Zeek: Log generating engine.
- Zed Language: Log querying language that allows performing keywoırd searches with filters and pipelines.
- ZNG Data Format: Data storage format that supports saving data streams.
- Electron and React: Cross-platform UI.

It comes with Premade queries which perform different tasks on the files split out from the pcap.
The Unique Network Connections and Transferred Data query is:
_path=="conn" | cut id.orig_h, id.resp_p, id.resp_h | sort | uniq
- Uses the connections log
- Grabs the client IP, the server Port and IP, and then filters for only the unique connections
Command Line Cheat Sheet

Windows Forensics
Tools:
- Eric Zimmermans tools
- KAPE - Kroll Artifact Parser and Extractor
- automates the collection and parsing of forensic artifacts and can help create a timeline of events.
- Autopsy - an open-source forensics platform that helps analyze data from digital media like mobile devices, hard drives, and removable drives.
- Volatility - a tool that helps perform memory analysis for memory captures from both Windows and Linux Operating Systems.
- Redline - an incident response tool developed and freely distributed by FireEye.
- Velociraptor - an advanced endpoint-monitoring, forensics, and response platform. It is open-source but very powerful.
Process
NIST SP-800-61 Incident Handling guide steps:
- Preparation
- Detection and Analysis
- Containment, Eradication, and Recovery
- Post-incident Activity
SANS Incident Handler’s handbook steps (PICERL):
- Preparation
- Identification
- Containment
- Eradication
- Recovery
- Lessons Learned
Windows Forensics 1
The Windows Registry is a collection of databases that contains the system’s configuration data. This configuration data can be about the hardware, the software, or the user’s information. It also includes data about the recently used files, programs used, or devices connected to the system. You can view the registry using regedit.exe, a built-in Windows utility to view and edit the registry.
If you only have access to a disk image, you must know where the registry hives are located on the disk. The majority of these hives are located in the C:\Windows\System32\Config directory and are:
- DEFAULT (mounted on
HKEY_USERS\DEFAULT) - SAM (mounted on
HKEY_LOCAL_MACHINE\SAM) - SECURITY (mounted on
HKEY_LOCAL_MACHINE\Security) - SOFTWARE (mounted on
HKEY_LOCAL_MACHINE\Software) - SYSTEM (mounted on
HKEY_LOCAL_MACHINE\System)
For Windows 7 and above, a user’s profile directory is located in C:\Users\<username>\ where the 9HIDDEN) hives are:
- NTUSER.DAT (mounted on HKEY_CURRENT_USER when a user logs in)
- located in the directory
C:\Users\<username>\.
- located in the directory
- USRCLASS.DAT (mounted on HKEY_CURRENT_USER\Software\CLASSES)
- located in the directory
C:\Users\<username>\AppData\Local\Microsoft\Windows
- located in the directory
There is another very important hive called the AmCache hive. This hive is located in C:\Windows\AppCompat\Programs\Amcache.hve. Windows creates this hive to save information on programs that were recently run on the system.
The transaction log for each hive is stored as a .LOG file in the same directory as the hive itself.
Registry backups are the opposite of Transaction logs. These are the backups of the registry hives located in the C:\Windows\System32\Config directory. These hives are copied to the C:\Windows\System32\Config\RegBack directory every ten days.
Data Acquisition
Tools:
- KAPE is a live data acquisition and analysis tool which can be used to acquire registry data. It is primarily a command-line tool but also comes with a GUI.
- Autopsy gives you the option to acquire data from both live systems or from a disk image.
- FTK Imager is similar to Autopsy
Exploring Windows Registry
Tools:
- AccessData’s Registry Viewer has a similar user interface to the Windows Registry Editor
- Eric Zimmerman’s Registry Explorer
- RegRipper is a utility that takes a registry hive as input and outputs a report that extracts data from some of the forensically important keys and values in that hive.
System Information and System Accounts
- OS Version
- To find the OS version, we can use the following registry key:
SOFTWARE\Microsoft\Windows NT\CurrentVersion
- To find the OS version, we can use the following registry key:
-
The hives containing the machine’s configuration data used for controlling system startup are called Control Sets. Commonly, we will see two Control Sets in the
SYSTEMhive on a machine. In most cases, ControlSet001 will point to the Control Set that the machine booted with, and ControlSet002 will be thelast known goodconfiguration. Their locations will be:SYSTEM\ControlSet001andSYSTEM\ControlSet002 -
Computer Name:
SYSTEM\CurrentControlSet\Control\ComputerName\ComputerName -
Time Zone:
SYSTEM\CurrentControlSet\Control\TimeZoneInformation - Network Interfaces:
SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Interfaces- The past networks a given machine was connected to can be found in the following locations:
SOFTWARE\Microsoft\Windows NT\CurrentVersion\NetworkList\Signatures\UnmanagedSOFTWARE\Microsoft\Windows NT\CurrentVersion\NetworkList\Signatures\Managed
- The past networks a given machine was connected to can be found in the following locations:
- Autostart Programs - The following registry keys include information about programs or commands that run when a user logs on.
NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\RunNTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\RunOnceSOFTWARE\Microsoft\Windows\CurrentVersion\RunOnceSOFTWARE\Microsoft\Windows\CurrentVersion\policies\Explorer\RunSOFTWARE\Microsoft\Windows\CurrentVersion\Run
-
SAM Hive and User Information:
SAM\Domains\Account\Users -
Recently open files:
NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs -
Microsoft Office Specific Recently Opened Documents:
NTUSER.DAT\Software\Microsoft\Office\VERSION - ShellBags - When any user opens a folder, it opens in a specific layout. Users can change this layout according to their preferences. These layouts can be different for different folders. We can find this info here:
USRCLASS.DAT\Local Settings\Software\Microsoft\Windows\Shell\BagsUSRCLASS.DAT\Local Settings\Software\Microsoft\Windows\Shell\BagMRUNTUSER.DAT\Software\Microsoft\Windows\Shell\BagMRUNTUSER.DAT\Software\Microsoft\Windows\Shell\Bags
- Open/Save and LastVisited Dialog MRUs - When we open or save a file, a dialog box appears asking us where to save or open that file from. It might be noticed that once we open/save a file at a specific location, Windows remembers that location. This implies that we can find out recently used files if we get our hands on this information. We can do so by examining the following registry keys:
NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\ComDlg32\OpenSavePIDlMRUNTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\ComDlg32\LastVisitedPidlMRU
- Windows Explorer Address/Search Bars:
NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\TypedPathsNTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\WordWheelQuery
- UserAssist - Windows keeps track of applications launched by the user using Windows Explorer for statistical purposes in the User Assist registry keys.
NTUSER.DAT\Software\Microsoft\Windows\Currentversion\Explorer\UserAssist\{GUID}\Count
- Shimcache - ShimCache is a mechanism used to keep track of application compatibility with the OS and tracks all applications launched on the machine.
- It is also called Application Compatibility Cache (AppCompatCache).
SYSTEM\CurrentControlSet\Control\Session Manager\AppCompatCache- We can use the following command to run the AppCompatCache Parser Utility:
AppCompatCacheParser.exe --csv <path to save output> -f <path to SYSTEM hive for data parsing> -c <control set to parse>
- AmCache - The AmCache hive is an artifact related to ShimCache. This performs a similar function to ShimCache, and stores additional data related to program executions.
C:\Windows\appcompat\Programs\Amcache.hve- Information about the last executed programs can be found at the following location in the hive:
Amcache.hve\Root\File\{Volume GUID}\
- BAM/DAM - Background Activity Monitor or BAM keeps a tab on the activity of background applications. Similar Desktop Activity Moderator or DAM is a part of Microsoft Windows that optimizes the power consumption of the device. Both of these are a part of the Modern Standby system in Microsoft Windows.
SYSTEM\CurrentControlSet\Services\bam\UserSettings\{SID}SYSTEM\CurrentControlSet\Services\dam\UserSettings\{SID}
- Device Identification - The following locations keep track of USB keys plugged into a system:
SYSTEM\CurrentControlSet\Enum\USBSTORSYSTEM\CurrentControlSet\Enum\USB- The following registry checks the last times they were connected/removed:
SYSTEM\CurrentControlSet\Enum\USBSTOR\Ven_Prod_Version\USBSerial#\Properties\{83da6326-97a6-4088-9453-a19231573b29}\####- Where ####:
- 0064 for first connection time
- 0066 for last connection time
- 0067 for last removal time
- Where ####:
- USB Device Volume Name:
SOFTWARE\Microsoft\Windows Portable Devices\Devices
Windows Forensics 2
FAT file systems
FAT - File Allocation Table
- was the default filesystem for Microsoft (NTFS now)
- The exFAT file system is now the default for SD cards larger than 32GB
- Supports these data structures:
- A cluster is a basic storage unit of the FAT file system. Each file stored on a storage device can be considered a group of clusters containing bits of information.
- A directory contains information about file identification, like file name, starting cluster, and filename length.
- The File Allocation Table is a linked list of all the clusters. It contains the status of the cluster and the pointer to the next cluster in the chain.
| Attribute | FAT12 | FAT16 | FAT32 | exFAT |
| —————————— | ———- | ———- | ———– | ———– |
| Addressable bits | 12 | 16 | 28 | |
| Max number of clusters | 4,096 | 65,536 | 268,435,456 | |
| Supported size of clusters | 512B - 8KB | 2KB - 32KB | 4KB - 32KB | 4KB to 32MB |
| Maximum Volume size | 32MB | 2GB | 2TB | 128PB |
*The maximum volume size for FAT32 is 2TB, but Windows limits formatting to only 32GB. However, volume sizes formatted on other OS with larger volume sizes are supported by Windows.
NTFS File System
New Technology File System (NTFS) developed by Microsoft to add a little more in terms of security, reliability, and recovery capabilities.
- Journaling - keeps a log of changes to the metadata in the volume.
- Access Controls
- Volume Shadow Copy - keeps track of changes made to a file, a user can restore previous file versions for recovery or system restore.
- Alternate Data Streams - a feature in NTFS that allows files to have multiple streams of data stored in a single file
Master File Table
Like the File Allocation Table, there is a Master File Table in NTFS. However, the Master File Table, or MFT, is much more extensive than the File Allocation Table. It is a structured database that tracks the objects stored in a volume. Therefore, we can say that the NTFS file system data is organized in the Master File Table. From a forensics point of view, the following are some of the critical files in the MFT:
- $MFT - the first record in the volume, this file contains a directory of all the files present on the volume.
- $LOGFILE - stores the transactional logging of the file system. It helps maintain the integrity of the file system in the event of a crash
- $UsnJrnl - Update Sequence Number (USN) Journal, It contains information about all the files that were changed in the file system and the reason for the change. It is also called the change journal.
MFT Explorer
Eric Zimmerman tool
Recovering Deleted Files
A disk image file is a file that contains a bit-by-bit copy of a disk drive. A bit-by-bit copy saves all the data in a disk image file, including the metadata, in a single file.
Autopsy
New Case is the first step
Evidence of Execution
Windows Prefetch Files: When a program is run in Windows, it stores its information for future use. This stored information is used to load the program quickly in case of frequent use. This information is stored in prefetch files which are located in the C:\Windows\Prefetch directory, have a .pf extension, and contain:
- the last run times of the application,
- the number of times the application was run,
- and any files and device handles used by the file
Syntax on file and directory:
PECmd.exe -f <path-to-Prefetch-files> --csv <path-to-save-csv>PECmd.exe -d <path-to-Prefetch-directory> --csv <path-to-save-csv>
Windows 10 Timeline: Windows 10 stores recently used applications and files in an SQLite database called the Windows 10 Timeline found here: C:\Users\<username>\AppData\Local\ConnectedDevicesPlatform\{randomfolder}\ActivitiesCache.db
WxTCmd.exe -f <path-to-timeline-file> --csv <path-to-save-csv>
Windows Jump Lists: Windows introduced jump lists to help users go directly to their recently used files from the taskbar. We can view jumplists by right-clicking an application’s icon in the taskbar, and it will show us the recently opened files in that application. This data is stored in the following directory:
C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations
JLECmd.exe -f <path-to-Jumplist-file> --csv <path-to-save-csv>
Shortcut Files: Windows creates a shortcut file for each file opened either locally or remotely. The shortcut files contain information about the first and last opened times of the file and the path of the opened file, along with some other data. Shortcut files can be found in the following locations:
C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Recent\
C:\Users\<username>\AppData\Roaming\Microsoft\Office\Recent\
LECmd.exe -f <path-to-shortcut-files> --csv <path-to-save-csv>
IE/Edge history: An interesting thing about the IE/Edge browsing history is that it includes files opened in the system as well, whether those files were opened using the browser or not. Hence, a valuable source of information on opened files in a system is the IE/Edge history. We can access the history in the following location:
C:\Users\<username>\AppData\Local\Microsoft\Windows\WebCache\WebCacheV*.dat
- The files/folders accessed appear with a
file:///*prefix in the IE/Edge history. Though several tools can be used to analyze Web cache data, you can use Autopsy to do so in the attached VM. For doing that, select Logical Files as a data source. - In the Window where Autopsy asks about ingest modules to process data, check the box in front of ‘Recent Activity’ and uncheck everything else.
Jump Lists: As we already learned in the last task, Jump Lists create a list of the last opened files. This information can be used to identify both the last executed programs and the last opened files in a system. Remembering from the last task, Jump Lists are present at the following location:
C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations
External Devices:
USB - When any new device is attached to a system, information related to the setup of that device is stored in the setupapi.dev.log. This log contains the device serial number and the first/last times when the device was connected.This log is present at the following location:
C:\Windows\inf\setupapi.dev.log
Shortcut Files: As we learned in the previous task, shortcut files are created automatically by Windows for files opened locally or remotely. These shortcut files can sometimes provide us with information about connected USB devices. It can provide us with information about the volume name, type, and serial number. Recalling from the previous task, this information can be found at:
C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Recent\
C:\Users\<username>\AppData\Roaming\Microsoft\Office\Recent\
Sysmon
+—-+—————————————-+
| # | Sysmon Event |
+—-+—————————————-+
| 1 | Process creation |
| 3 | Network connection |
| 5 | Process terminated |
| 7 | Image loaded |
| 8 | CreateRemoteThread |
| 9 | RawAccessRead |
| 10 | ProcessAccess |
| 11 | FileCreate |
| 12 | RegistryEvent (Object create & delete) |
| 13 | RegistryEvent (Value Set) |
| 14 | RegistryEvent (Key & Value Rename) |
| 15 | FileCreateStreamHash |
| 22 | DNSEvent (DNS query) |
+—-+—————————————-+
Windows Local Persistence
Startup folder
Each user has a folder under C:\Users\<your_username>\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup
where you can put executables to be run whenever the user logs in.
Run / RunOnce
You can also force a user to execute a program on logon via the registry. Instead of delivering your payload into a specific directory, you can use the following registry entries to specify applications to run at logon:
- HKCU\Software\Microsoft\Windows\CurrentVersion\Run
- HKCU\Software\Microsoft\Windows\CurrentVersion\RunOnce
- HKLM\Software\Microsoft\Windows\CurrentVersion\Run
- HKLM\Software\Microsoft\Windows\CurrentVersion\RunOnce
Splunk
Wireshark 2
Statistics:
- Resolved Address
- Can check hostnames here
- Protocol Hierarchy
- Number of IPv4 conversations
- Conversations
- How many bytes were transferred
- Endpoints
- Number of IP addresses linked with each city
- IP addresses which are linked to AS Organization
- Protocol Details
- Can select IPv4 vs IPv6 from the bottom of the Statistics dropdown
- DNS
- HTTP
Display filter syntax:
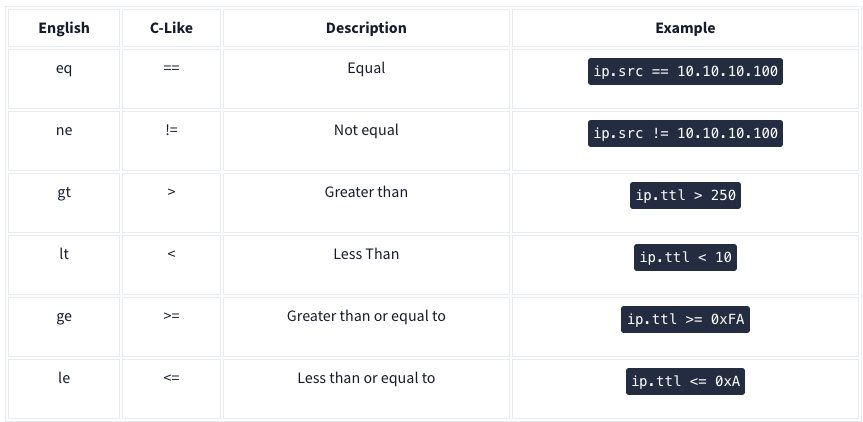
Logical expressions:

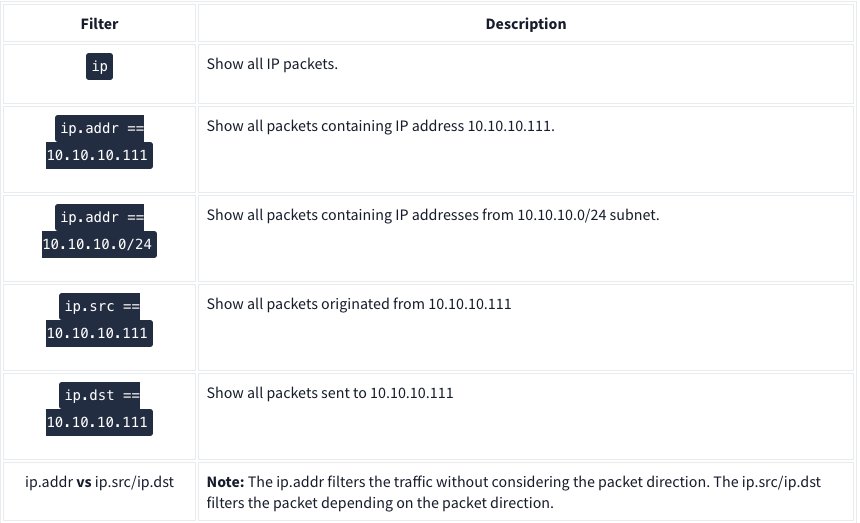
IP Filters:
TCP and UDP Filters:
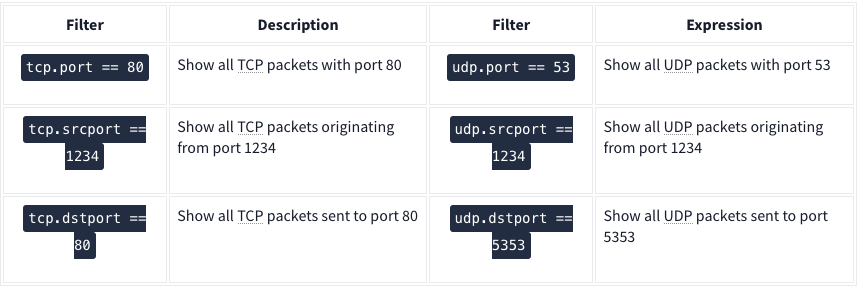
| Application Level Protocol Filters | HTTP and DNS |

Use the ”Analyse –> Display Filter Expression” when you can’t remember
Advanced Operators
- contains
- Ex:
http.server contains "Apache"
- Ex:
- matches - Search a pattern of a regular expression. It is case insensitive, and complex queries have a margin of error.
- Ex:
http.hosts matches "\.(php|html)" - Lists all HTTP packets where packets’ “host” fields match keywords “.php” or “.html”.
- Ex:
- in - Search a value or field inside of a specific scope/range.
- Ex:
tcp.port in {80 443 8080}
- Ex:
- upper - Convert a string value to uppercase
- Ex:
upper(http.server) contains "APACHE"
- Ex:
- lower - Convert a string value to lowercase.
- Ex:
lower(http.server) contains "apache"
- Ex:
- string - Convert a non-string value to a string.
- Ex:
string(frame.number) matches "[13579]$" - Finds all frames with odd numbers
- Ex:
Bookmarks
Right click on search bar and click save this query
Profiles
Save queries to different profiles such as one for CTFs and one for Network Troubleshooting
Traffic Analysis
Nmap Scans
KAPE
Kroll Artifact Parser and Extractor (KAPE) parses and extracts Windows forensics artifacts. KAPE serves two primary purposes:
- collect files
- process the collected files as per the provided options.
The collection of files (targets) KAPE adds the files to a queue and copies them in two passes. In the first pass, it copies the files that it can. This works for files that the OS has not locked. The rest of the files are passed to a secondary queue. The secondary queue is processed using a different technique that uses raw disk reads to bypass the OS locks and copy the files. The copied files are saved with original timestamps and metadata and stored in a similar directory structure.

Targets are the artifacts that need to be collected from a system or image and copied to our provided destination. For example, Windows Prefetch is a forensic artifact for evidence of execution so that we can create a Target for it. Similarly, we can also create Targets for the registry hives. In short, Targets copy files from one place to another.
Target is defined for KAPE with a TKAPE file which contains information about the artifact that we want to collect, such as the path, category, and file masks to collect. As an example, below is how the Prefetch Target is defined.
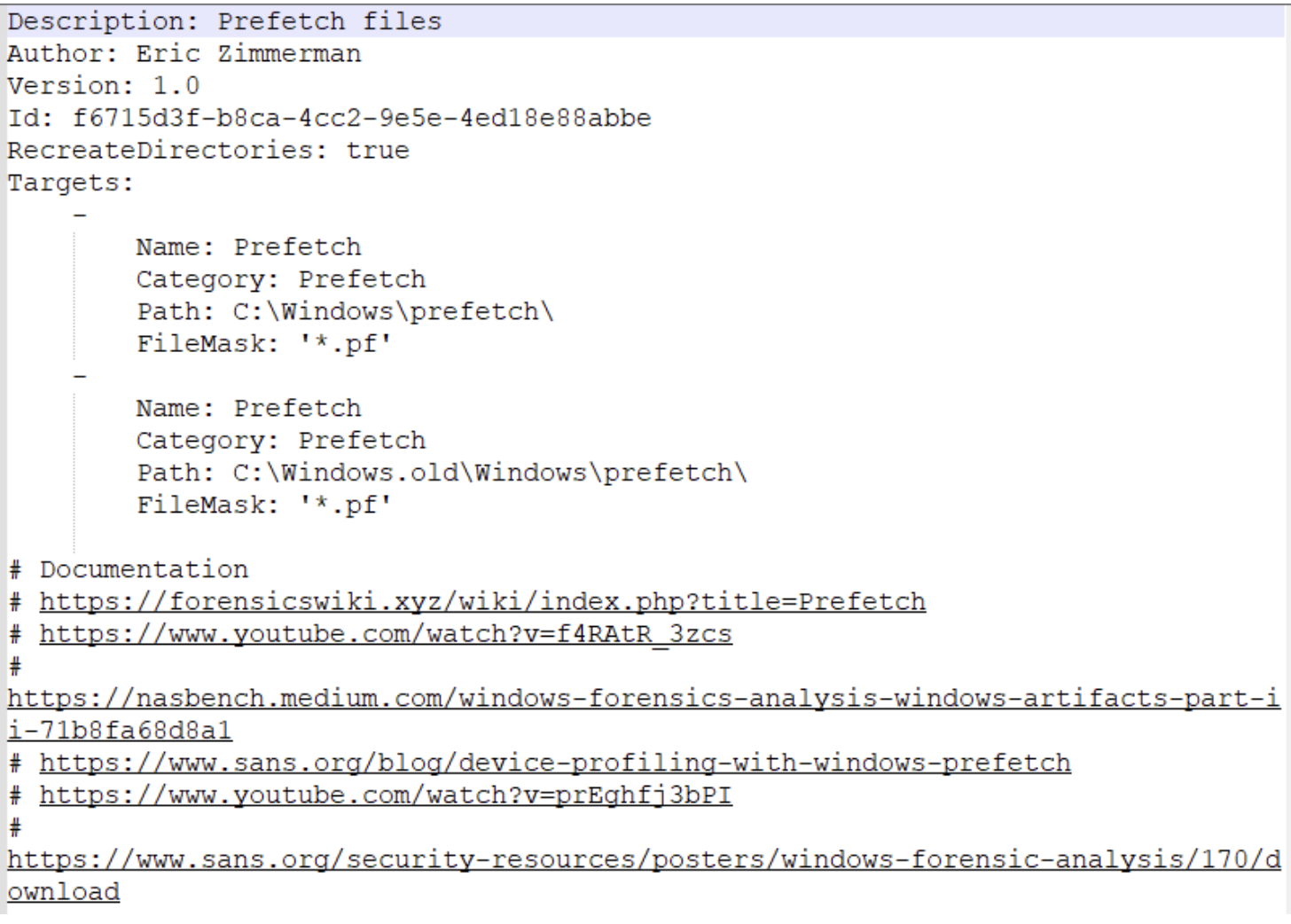
^ This TKAPE file tells KAPE to collect files with the file mask *.pf from the path C:\Windows\prefetch and C:\Windows.old\prefetch.
Compound Targets - KAPE also supports Compound Targets. These are Targets that are compounds of multiple other targets. As mentioned in the previous tasks, KAPE is often used for quick triage collection and analysis. The purpose of KAPE will not be fulfilled if we have to collect each artifact individually. Therefore, Compound Targets help us collect multiple targets by giving a single command. Examples of Compound Targets include !BasicCollection, !SANS_triage and KAPEtriage. We can view the Compound Targets on the path KAPE\Targets\Compound. The following image shows what a Compound Target for evidence of execution looks like:
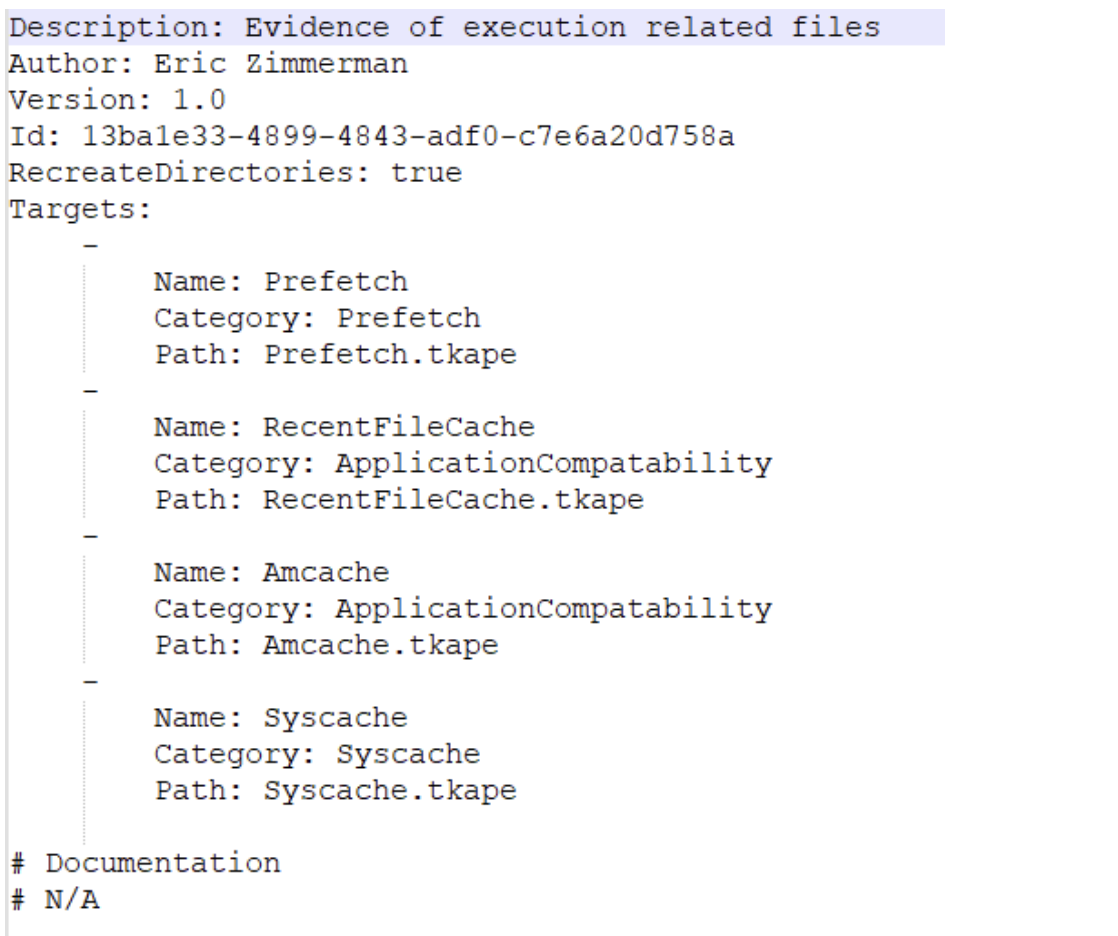
^ The above Compound Target will collect evidence of execution from Prefetch, RecentFileCache, AmCache, and Syscache Targets.
If you have created some Targets that you don’t want to sync with the KAPE Github repository, you can place them in the !Local directory. These can be Targets that are specific to your environment.
Module Options
Modules, in KAPE’s lexicon, run specific tools against the provided set of files.
- Runs the commands and stores the output as TXT or CSV
Files with the .mkape extension are understood as Modules by KAPE
The bin directory contains executables that we want to run on the system but are not natively present on most systems. KAPE will run executables either from the bin directory or the complete path. An example of files to be kept in the bin directory are Eric Zimmerman’s tools, which are generally not present on a Windows system.
This is important because each of the .mkape files contains information that includes an executable and what we want it to do. So we may need additional executables that are not present on the system.
KAPE GUI
KAPE CLI
We can see from the above screenshot that while collecting Targets, the switches tsource, target and tdest are required. Similarly, when processing files using Modules, module and mdest are required switches. The other switches are optional as per the requirements of the collection.
D:\KAPE>kape.exe
KAPE version 1.1.0.1 Author: Eric Zimmerman (kape@kroll.com)
tsource Target source drive to copy files from (C, D:, or F:\ for example)
target Target configuration to use
tdest Destination directory to copy files to. If --vhdx, --vhd or --zip is set, files will end up in VHD(X) container or zip file
tlist List available Targets. Use . for Targets directory or name of subdirectory under Targets.
tdetail Dump Target file details
tflush Delete all files in 'tdest' prior to collection
tvars Provide a list of key:value pairs to be used for variable replacement in Targets. Ex: --tvars user:eric would allow for using %user% in a Target which is replaced with eric at runtime. Multiple pairs should be separated by ^
tdd Deduplicate files from --tsource (and VSCs, if enabled) based on SHA-1. First file found wins. Default is TRUE
msource Directory containing files to process. If using Targets and this is left blank, it will be set to --tdest automatically
module Module configuration to use
mdest Destination directory to save output to
mlist List available Modules. Use . for Modules directory or name of subdirectory under Modules.
mdetail Dump Module processors details
mflush Delete all files in 'mdest' prior to running Modules
mvars Provide a list of key:value pairs to be used for variable replacement in Modules. Ex: --mvars foo:bar would allow for using %foo% in a module which is replaced with bar at runtime. Multiple pairs should be separated by ^
mef Export format (csv, html, json, etc.). Overrides what is in Module config
sim Do not actually copy files to --tdest. Default is FALSE
vss Process all Volume Shadow Copies that exist on --tsource. Default is FALSE
vhdx The base name of the VHDX file to create from --tdest. This should be an identifier, NOT a filename. Use this or --vhd or --zip
vhd The base name of the VHD file to create from --tdest. This should be an identifier, NOT a filename. Use this or --vhdx or --zip
zip The base name of the ZIP file to create from --tdest. This should be an identifier, NOT a filename. Use this or --vhdx or --vhd
scs SFTP server host/IP for transferring *compressed VHD(X)* container
scp SFTP server port. Default is 22
scu SFTP server username. Required when using --scs
scpw SFTP server password
scd SFTP default directory to upload to. Will be created if it does not exist
scc Comment to include with transfer. Useful to include where a transfer came from. Defaults to the name of the machine where KAPE is running
s3p S3 provider name. Example: spAmazonS3 or spGoogleStorage. See 'https://bit.ly/34s9nS6' for list of providers. Default is 'spAmazonS3'
s3r S3 region name. Example: us-west-1 or ap-southeast-2. See 'https://bit.ly/3aNxXhc' for list of regions by provider
s3b S3 bucket name
s3k S3 Access key
s3s S3 Access secret
s3st S3 Session token
s3kp S3 Key prefix. When set, this value is used as the beginning of the key. Example: 'US1012/KapeData'
s3o When using 'spOracle' provider, , set this to the 'Object Storage Namespace' to use
s3c Comment to include with transfer. Useful to include where a transfer came from. Defaults to the name of the machine where KAPE is running
s3url S3 Presigned URL. Must be a PUT request vs. a GET request
asu Azure Storage SAS Uri
asc Comment to include with transfer. Useful to include where a transfer came from. Defaults to the name of the machine where KAPE is running
zv If true, the VHD(X) container will be zipped after creation. Default is TRUE
zm If true, directories in --mdest will be zipped. Default is FALSE
zpw If set, use this password when creating zip files (--zv | --zm | --zip)
hex Path to file containing SHA-1 hashes to exclude. Only files with hashes not found will be copied
debug Show debug information during processing
trace Show trace information during processing
gui If true, KAPE will not close the window it executes in when run from gkape. Default is FALSE
ul When using _kape.cli, when true, KAPE will execute entries in _kape.cli one at a time vs. in parallel. Default is FALSE
cu When using _kape.cli, if true, KAPE will delete _kape.cli and both Target/Module directories upon exiting. Default is FALSE
sftpc Path to config file defining SFTP server parameters, including port, users, etc. See documentation for examples
sftpu When true, show passwords in KAPE switches for connection when using --sftpc. Default is TRUE
rlc If true, local copy of transferred files will NOT be deleted after upload. Default is FALSE
guids KAPE will generate 10 GUIDs and exit. Useful when creating new Targets/Modules. Default is FALSE
sync If true, KAPE will download the latest Targets and Modules from specified URL prior to running. Default is https://github.com/EricZimmerman/KapeFiles/archive/master.zip
ifw If false, KAPE will warn if a process related to FTK is found, then exit. Set to true to ignore this warning and attempt to proceed. Default is FALSE
Variables: %d = Timestamp (yyyyMMddTHHmmss)
%s = System drive letter
%m = Machine name
Examples: kape.exe --tsource L: --target RegistryHives --tdest "c:\temp\RegistryOnly"
kape.exe --tsource H --target EvidenceOfExecution --tdest "c:\temp\default" --debug
kape.exe --tsource \\server\directory\subdir --target Windows --tdest "c:\temp\default_%d" --vhdx LocalHost
kape.exe --msource "c:\temp\default" --module LECmd --mdest "c:\temp\modulesOut" --trace --debug
Short options (single letter) are prefixed with a single dash. Long commands are prefixed with two dashes
Full documentation: https://ericzimmerman.github.io/KapeDocs/
Autopsy
Autopsy is the premier open source forensics platform which is fast, easy-to-use, and capable of analysing all types of mobile devices and digital media. Its plug-in architecture enables extensibility from community-developed or custom-built modules. Autopsy evolves to meet the needs of hundreds of thousands of professionals in law enforcement, national security, litigation support, and corporate investigation.
Basic workflow:
- Create/open the case for the data source you will investigate
- Case Name: The name you wish to give to the case
- Base Directory: The root directory that will store all the files specific to the case (the full path will be displayed)
- Case Type: Specify whether this case will be local (Single-user) or hosted on a server where multiple analysts can review (Multi-user)
- Select the data source you wish to analyze
- Supported Disk Image Formats:
- Raw Single (For example: *.img, *.dd, *.raw, *.bin)
- Raw Split (For example: *.001, *.002, *.aa, *.ab, etc)
- EnCase (For example: *.e01, *.e02, etc)
- Virtual Machines (For example: *.vmdk, *.vhd)
- Supported Disk Image Formats:
- Configure the ingest modules to extract specific artifacts from the data source
- Ingest module are basically Autopsy plugins, designed to analyze and retrieve specific data from the drive
- The
Interesting Files Identifiermodule shows E-Mail Messages, Interesting Items, and Accounts, for example.
- Review the artifacts extracted by the ingest modules
- Create the report
The User Interface
The Tree Viewer has five top-level nodes:
- Data Sources - all the data will be organized as you would typically see it in a normal Windows File Explorer.
- Views - files will be organized based on file types, MIME types, file size, etc.
- Results - as mentioned earlier, this is where the results from Ingest Modules will appear.
- Tags - will display files and/or results that have been tagged (read more about tagging here).
- Reports - will display reports either generated by modules or the analyst (read more about reporting here).
When a volume, file, folder, etc., is selected from the Tree Viewer, additional information about the selected item is displayed in the Result Viewer which three tabs: Table, Thumbnail, and Summary.
In the Views tree node, files are categorized by File Types - By Extension, By MIME Type, Deleted Files, and By File Size.
- Tip: When it comes to File Types, pay attention to this section. An adversary can rename a file with a misleading file extension. So the file will be ‘miscategorized’ By Extension but will be categorized appropriately by MIME Type.
From the Table tab in the Result Viewer, if you click any folder/file, additional information is displayed in the Contents Viewer pane.
- Three columns might not be quickly understood what they represent.
- S = Score - Shows a red exclamation point for a folder/file marked/tagged as notable and a yellow triangle pointing downward for a folder/file marked/tagged as suspicious.
- C = Comment
- O = Occurrence
Keyword Search - You know
Status Area - When Ingest Modules run, a progress bar (along with the percentage completed) will be displayed in this area.
The Data Sources Summary provides summarized info in nine different categories.
Generate Report - Note that reports don’t have additional search options, so you must manually find artifacts for the event of interest.
Additional Tools
The Timeline tool is composed of three areas:
- Filters: Narrow the events displayed based on the filter criteria
- Events: The events are displayed here based on the View Mode
- Files/Contents: Additional information on the event(s) is displayed in this area
There are three view modes:
- Counts: The number of events is displayed in a bar chart view
- Details: Information on events is displayed, but they are clustered and collapsed, so the UI is not overloaded
- List: The events are displayed in a table view
Please refer to the Autopsy documentation for the following visualisation tool:
- Images/Videos: http://sleuthkit.org/autopsy/docs/user-docs/4.12.0/image_gallery_page.html
- Communications: http://sleuthkit.org/autopsy/docs/user-docs/4.12.0/communications_page.html
- Timeline: http://sleuthkit.org/autopsy/docs/user-docs/4.12.0/timeline_page.html
Linux Forensics
OS and Account Information
OS release information: cat /etc/os-release
User accounts: cat /etc/password | column -t -s :
Group Information: cat /etc/group
Sudoers list: sudo cat /etc/sudoers
Login information: In the /var/log directory, we can find log files of all kinds including wtmp and btmp. The btmp file saves information about failed logins, while the wtmp keeps historical data of logins. These files are not regular text files that can be read using cat, less or vim; instead, they are binary files, which have to be read using the last utility. You can learn more about the last utility by reading its man page.
sudo last -f /var/log/wtmp
Authentication logs: cat /var/log/auth.log |tail
System Configuration
Hostname: cat /etc/hostname
Timezone: cat /etc/timezone
Network Configuration: cat /etc/network/interfaces
ip address show
Active network connections: netstat -natp
Running processes: ps aux
DNS information: cat /etc/hosts
- The information about DNS servers that a Linux host talks to for DNS resolution is stored in the resolv.conf file. Its location is
/etc/resolv.conf. cat /etc/resolv.conf
Persistence mechanisms
Cron jobs - Cron jobs are commands that run periodically after a set amount of time. A Linux host maintains a list of Cron jobs in a file located at /etc/crontab.
cat /etc/crontab
Service startup - Like Windows, services can be set up in Linux that will start and run in the background after every system boot. A list of services can be found in the /etc/init.d directory.
ls /etc/init.d
.Bashrc - When a bash shell is spawned, it runs the commands stored in the .bashrc file. This file can be considered as a startup list of actions to be performed. Hence it can prove to be a good place to look for persistence.
cat ~/.bashrc
Evidence of execution
Sudo execution history - All the commands that are run on a Linux host using sudo are stored in the auth log.
cat /var/log/auth.log* |grep -i $COMMAND|tail
Bash history - Any commands other than the ones run using sudo are stored in the bash history.
cat ~/.bash_history
Files accessed using vim - The Vim text editor stores logs for opened files in Vim in the file named .viminfo in the home directory.
cat ~/.viminfo
Log files
Syslog - The Syslog contains messages that are recorded by the host about system activity. The detail which is recorded in these messages is configurable through the logging level. We can use the cat utility to view the Syslog, which can be found in the file /var/log/syslog. Since the Syslog is a huge file, it is easier to use tail, head, more or less utilities to help make it more readable.
cat /var/log/syslog* | head
Auth logs - The auth logs contain information about users and authentication-related logs.
cat /var/log/auth.log* | head
Third-party logs - Similar to the syslog and authentication logs, the /var/log/ directory contains logs for third-party applications such as webserver, database, or file share server logs.
ls /var/logthencat /var/log/$example/$example.log